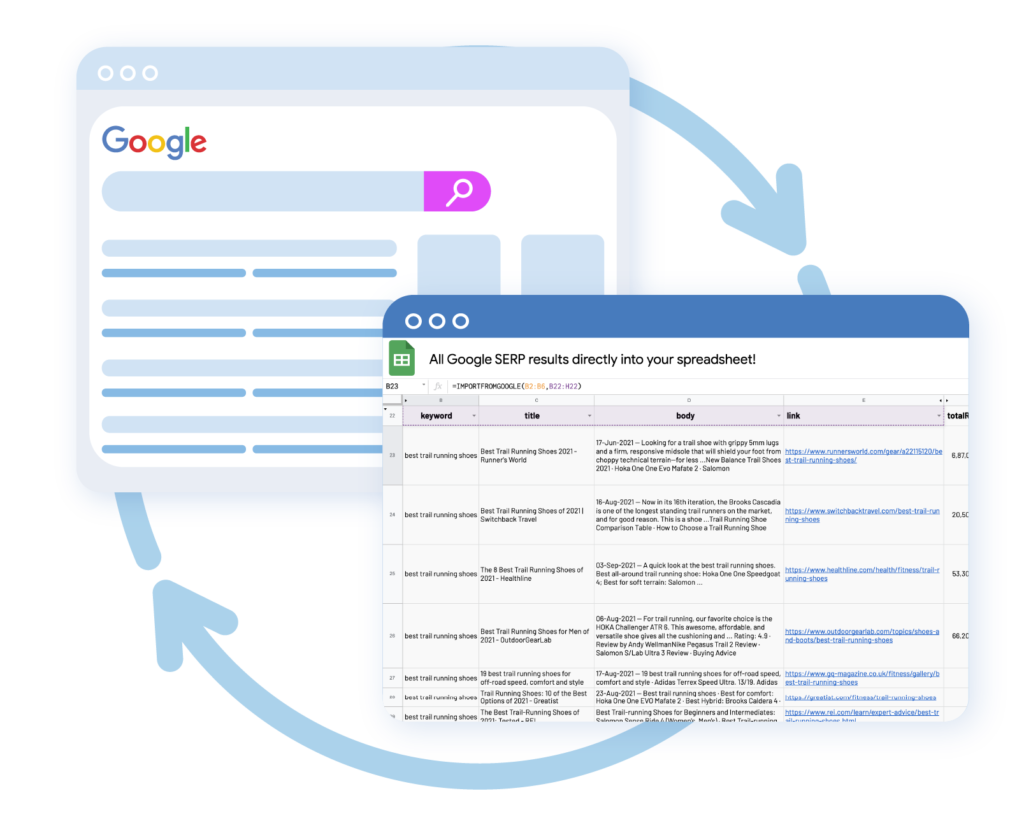
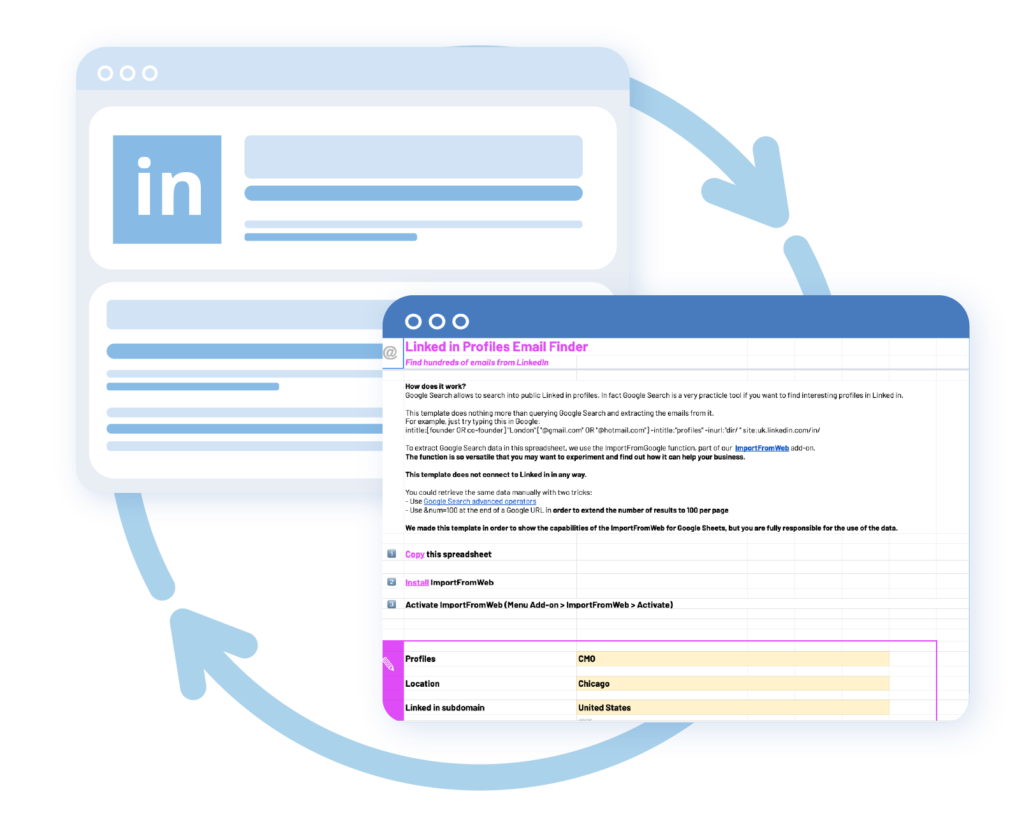
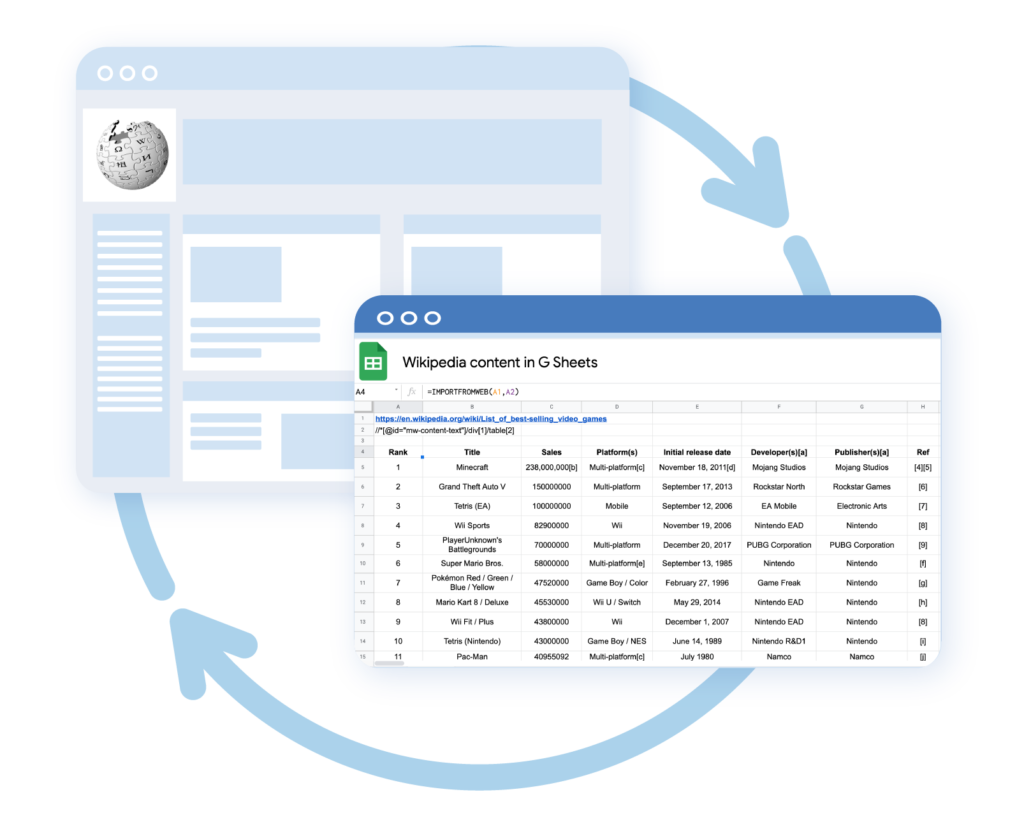
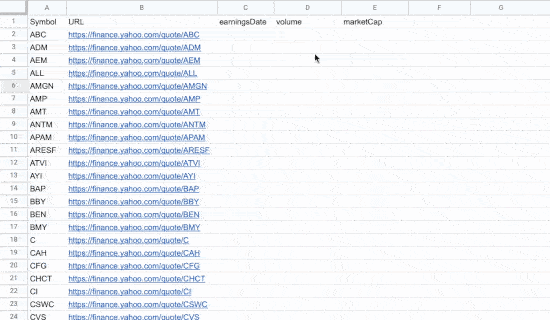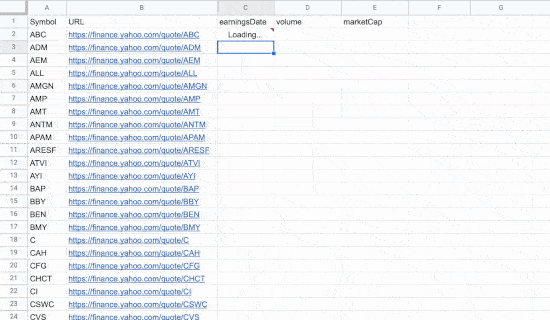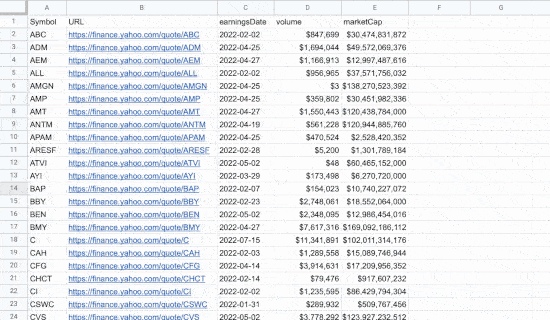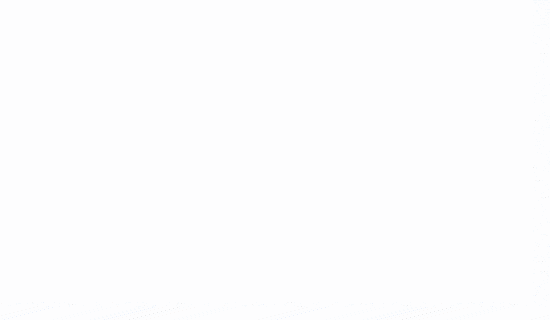
1 crédit est débité par URL scrapée tous les 24 heures.
Si vous scrapez exactement la même page plusieurs fois en 24 heures, ce n’est pas décompté. (par exemple pour récupérer le titre, email, nom, etc)
Au delà de 24 heures, l’URL scrapée débite à nouveau du crédit.
Cela veut aussi dire qu’il y a un système de cache de 24h. Si le contenu sur le site a été actualisé il y a moins de 24 heures, vous devrez donc attendre 24 heures pour que la nouvelle version de la page soit scrapée.
IMPORTANT: Si vous avez beaucoup de lignes qui utilisent la formule « ScrapMe », pensez impérativement à sauvegarder les valeurs extraites de votre Google Sheets dès que l’extraction est terminée. En effet vous avez 24h pour le faire sans quoi, cela relancera le scraping lorsque vous rechargerez votre fichier Google Sheet.
Pour cela:
1) Sélectionnez toutes les cellules où a été extrait le contenu
2) Faites « Copier »
3) Ensuite faire un « Collage spécial » -> « Valeur uniquement »
4) Voila vous avez sauvegardé les valeurs